Modern enterprise storage for primary workloads aims at three crucial parameters wherein block storage wins. These are:
- Quick provisioning of the large-scale storage capacity,
- Retrieving the data quickly whenever you want; and
- A faster, efficient, and secured data transportation.
Luckily, the block storage system for databases fulfills all these requirements. Today, more and more businesses have realized its flexibility and versatility in storing applications or file systems. Obviously, choosing the right storage system solely depends upon your specific storage requirements and their impact on the speed and performance of IT operations. But what makes this storage architecture a popular choice for most enterprises? Let’s find out.
What is Block-Level Data Storage?
Block storage or block-level storage is a type of IT architecture that stores data in the form of a file system. The block-level storage model store the data files in volumes on NAS (Network Attached Storage) )/ SAN (Storage Area Network). Some of the best benefits that block-based cloud storage offers are:
- In a block storage system, you can break the data into independent fixed-size blocks or pieces. Each block works as an individual storage hard drive. This lets you save the data by allocating the size of block volume to a server operating system. Also, you can partition each block and configure the data to work with any operating system. However, you must access the files via an operating system as a mounted drive volume.
- You can retrieve data easily as this storage type lets you distribute the data across multiple environments.

- Block storage supports static content storage that lets you store static transactional information. For example, you can store transactional databases, computing logs, etc.
- Each block has a unique identifier (ID) that include an address stored in the object. In effect, the server operating systems can track and manage these blocks of data easily.
- You can attach or mount cloud block storage volume on a server running on any operating system. But you must partition, format, and then *mount it. (*Mounting is the process of attaching a drive or formatted partition to a directory).
- You can directly access the block file as a a mapped drive or a local hard drive using the NAS or Network Operating System once the volume drive gets mounted.
- Operating systems can access the blocks via Fiber Channel or iSCSI connectivity.
How Does Block-Level Storage Work?
Unlike object storage, you can store the data in fixed-sized blocks. This makes it easy to index and search the data by adding context to the file through block storage metadata. You can split each block into multiple, evenly sized blocks on the Storage Area Network (SAN). The storage network efficiently manages data distribution across multiple physical devices. Block storage distributes data files across multiple environments. As a result, you easily locate the correct address of the blocks & retrieve data quickly with low-latency access.
Based on the users’ or application request for file retrieval, the SAN system gets the block and presents the file. The data stored in each block maintains its integrity and can be accessed independently without affecting other blocks.
The SAN application lets you configure the blocks to run databases or transactions efficiently, supporting high-performance applications. As a result, you can easily overwrite the blocks or applications that are changing through data write operations. Also, you can configure the blocks to run applications like databases or transactions that demand continuous accessibility, modifications, and security. Again, if you are creating new file systems including new technology file system or its variants, or deleting older files in servers, the older versions will still be available as persistent storage.
Block-level storage plays a critical role in organizing and storing all your enterprise applications
Block-Based Storage Use Cases
- You can easily manage database operations and mission-critical applications with block storage as file system permissions are quite familiar, and the system manages data efficiently across multiple servers.
- Critical application files for database storage such as Microsoft SharePoint, Microsoft Exchange, SAP, or Oracle require block storage solutions for optimal performance.
- VMware virtual machines such as VMware use block level storage since it supports industry-standard hypervisors (VMware, Microsoft Hyper-V, KVM, Citrix (formerly XenServer)), providing high performance for virtual machine operations.
- Block storage uses RAID technique (a redundant array means of storing information) that balances the input/output (I/O) operations for block volumes. In turn, this ensures high availability, data protection, and high performance across large data volumes.
- You can use this storage medium for mission-critical applications such as the Microsoft Exchange since traditional file system and file based storage solutions don’t support the Exchange databases effectively.
- You can locally attach the storage via a SAN working in conjunction with network protocol such as iSCSI, providing direct access to storage resources.
So you see, block storage work best as the storage capacity can adapt with your growing data size. Not only it offers the simplest way to store data, but also it is optimized for higher performance and scalability across storage solutions. This lets you fine-tune server performance & change the volume types without any extra cost involved, making it easy to implement block storage across your infrastructure.
Indeed, block as a storage solution enjoys certain distinct advantages for general-purpose workloads. Let’s count on them:
Key Benefits of Block Storage
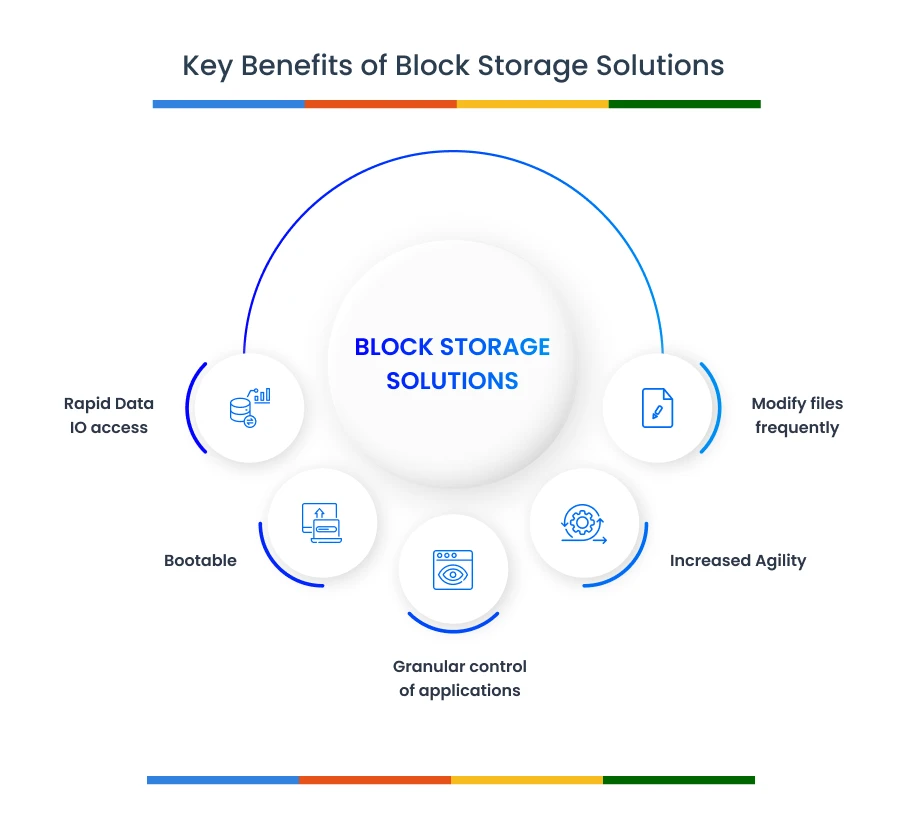
- Rapid Data IO access: Since block-level storage stores data in a single block with its own address, there are no I/O bottlenecks. This storage type supports most of the high performance applications residing in blocks. Henceforth, you can easily organize the data in block units with context set as isolated containers. Besides, such a layout lets you directly access individual data blocks to write data while reducing file system overheads. This can drastically speed up the performance of input-output operations per second (IOPS) for database servers (DB Server) such as caching, database operations, log files, etc., providing low-latency performance.
- Modify files frequently: You can easily modify backup media files whenever you want, as you have access to the specific required blocks in the volumes, enabling fast access to actual data without processing the entire file.
- Granular control of applications: Several high-performance applications reside in the block-level architecture. These applications can perform several functions native to individual OS platforms Using server-based operating systems, you can control data access & permissions privileges to make provisions for data storage.
- Increased Agility: Of course, you need to scale storage up and down as per increasing storage demands. This is where this storage architecture offers the flexibility to organize the file system in a logical data structure of storage volumes across storage resources. The result? You can easily transfer data from one server to another. Moreover, such a storage system supports the Internet Small Computer Systems Interface (iSCSI) Protocol. With a distributed file system across multi-client environments, you can easily export files for remote storage, temporary storage, and disaster recovery purposes.
- Bootable: Block storage allows booting a server from a network-attached cloud storage volume remotely. This way, you can move the system disk from local to remote directly, utilizing aws block storage capabilities.
Types of Block Storage in the Cloud
Interestingly, block storage takes over other options of storing data when it comes to faster data access. It’s important to realize that the larger the block size, the faster the input/output per second (IOPs). So, if you are choosing the correct block size, you can optimize access speed, modify files, and achieve high performance for data blocks across large data volumes. But you must go for the right storage strategy that can optimize cost and achieve peak efficiency. So, which storage service type is right for your workload needs? Notable examples of AWS storage types include Amazon EFS, Amazon EBS, Amazon S3and . Again, Azure storage and Google Cloud Storage are two different service models that provide storage in standard and premium versions.
Backup Your Block Repositories Securely With Zmanda
To achieve the best ROI, you must understand what block storage is and the unique identifier advantages that it has to offer. Indeed, this type of data storage is highly flexible as it lets you create additional storage by adding or attaching new blocks without sacrificing performance, making it easy to deploy block storage across your infrastructure. Zmanda offers a wide range of flexible block storage solutions for backups, including tape, tape libraries, disks (DAS, NAS & SAN, file servers, RAID), & optical jukeboxes. For quick recovery of databases, Zmanda makes it easier for customers to configure Amazon S3 storage. Besides, Zmanda validates each block that contains a performance tier residing in Amazon S3. As a result, you can access data faster with locally hosted NAS or direct-attached storage, providing low latency access to your stored data. As an open-source backup, Zmanda’s DR integration with Google cloud storage, Azure storage, and AWS storage provides cloud-native backup support for major public cloud providers.
Do you want to know how we can help maximize the backup experience for block storage volumes? Get in touch with us or visit our backup and disaster recovery solution page.