How Zmanda Pro works
1. Prevent data loss from the start
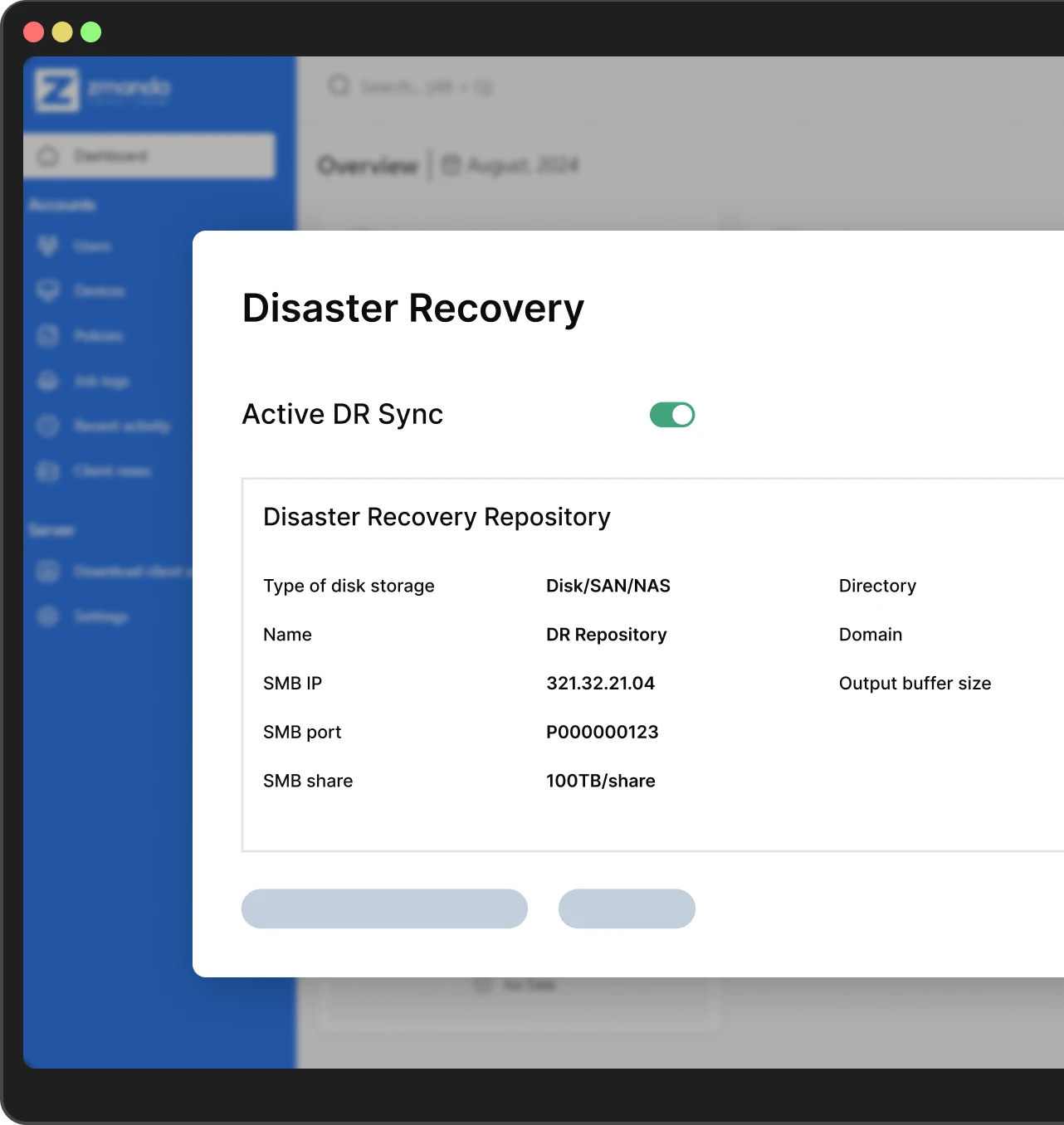
Preserve your data with immutable WORM storage and air-gapped backups, shielded from edits and deletions. Achieve 3-2-1-1 backup compliance in just two clicks with Zmanda Cloud Storage.
2. Prepare for business continuity
Strategically replicate Zmanda backup servers and storage across on-prem and cloud locations for business continuity. Use restore simulation to perform disaster recovery drills and test your system resilience.
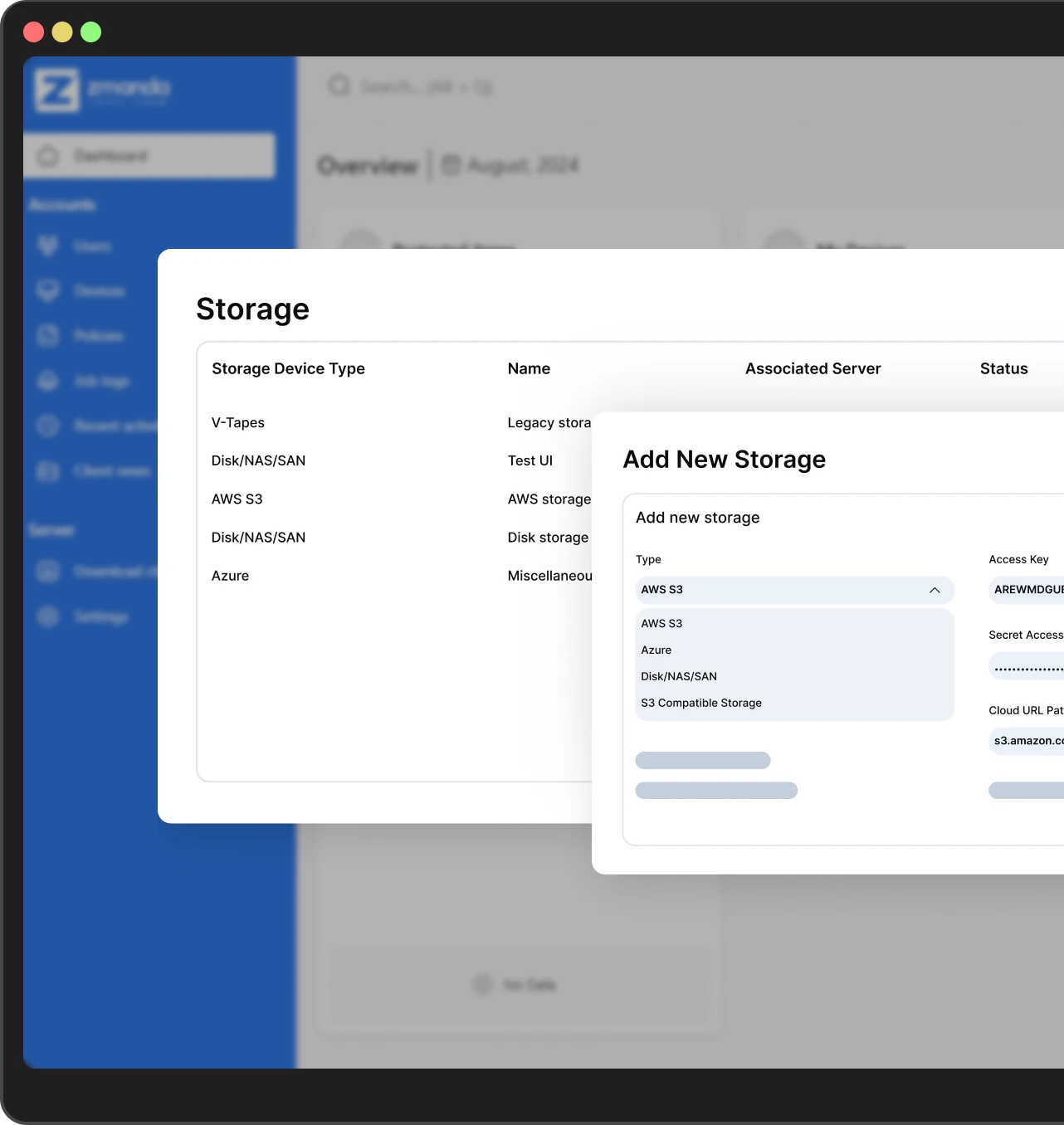
3. Detect threats early
Integrate Zmanda Pro with your existing SIEM platforms to enable real-time monitoring and alerting. Check data integrity with software-level (SHA-256 hash) and storage-level (high-speed ZFS checksum) corruption checks.
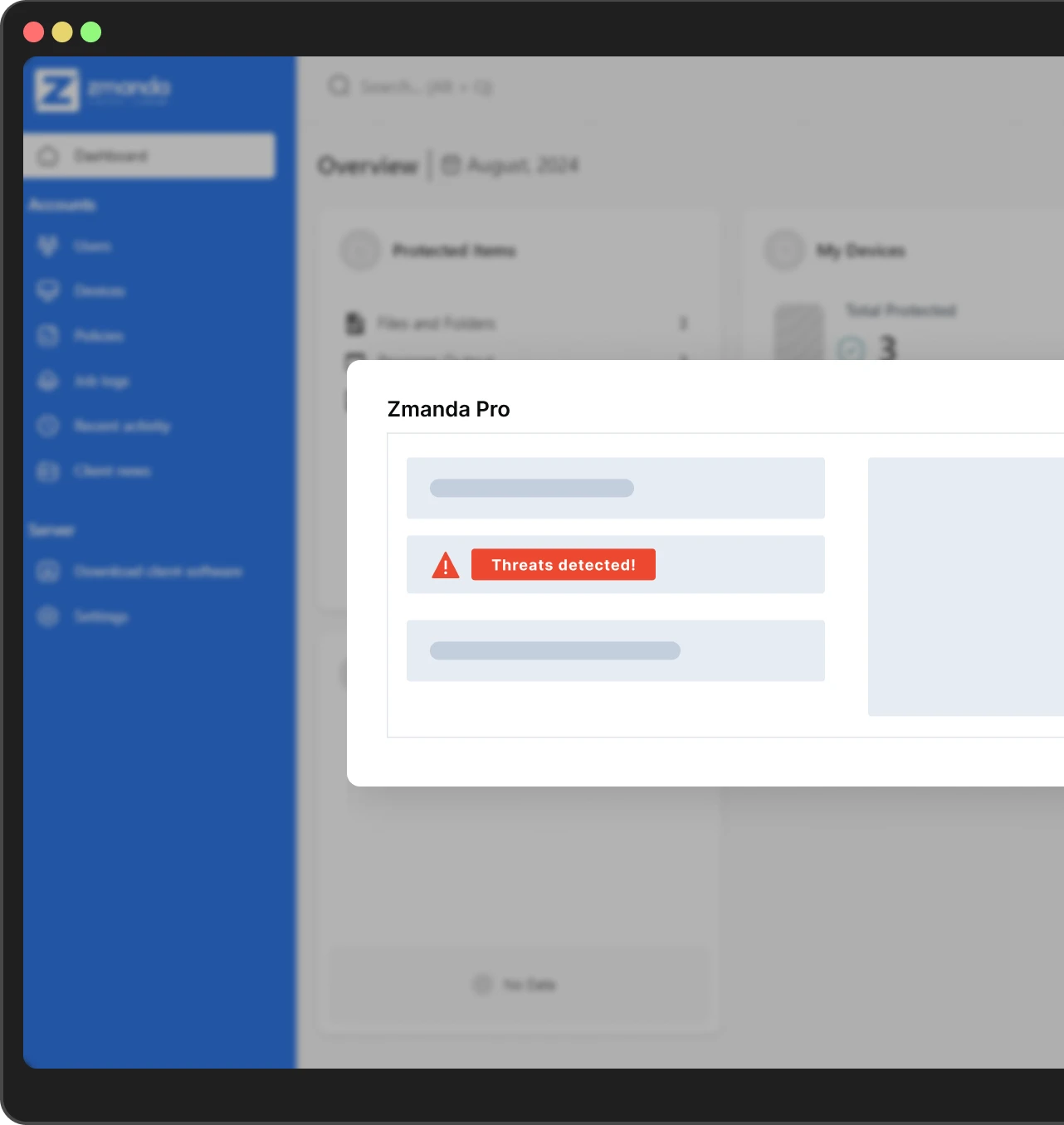
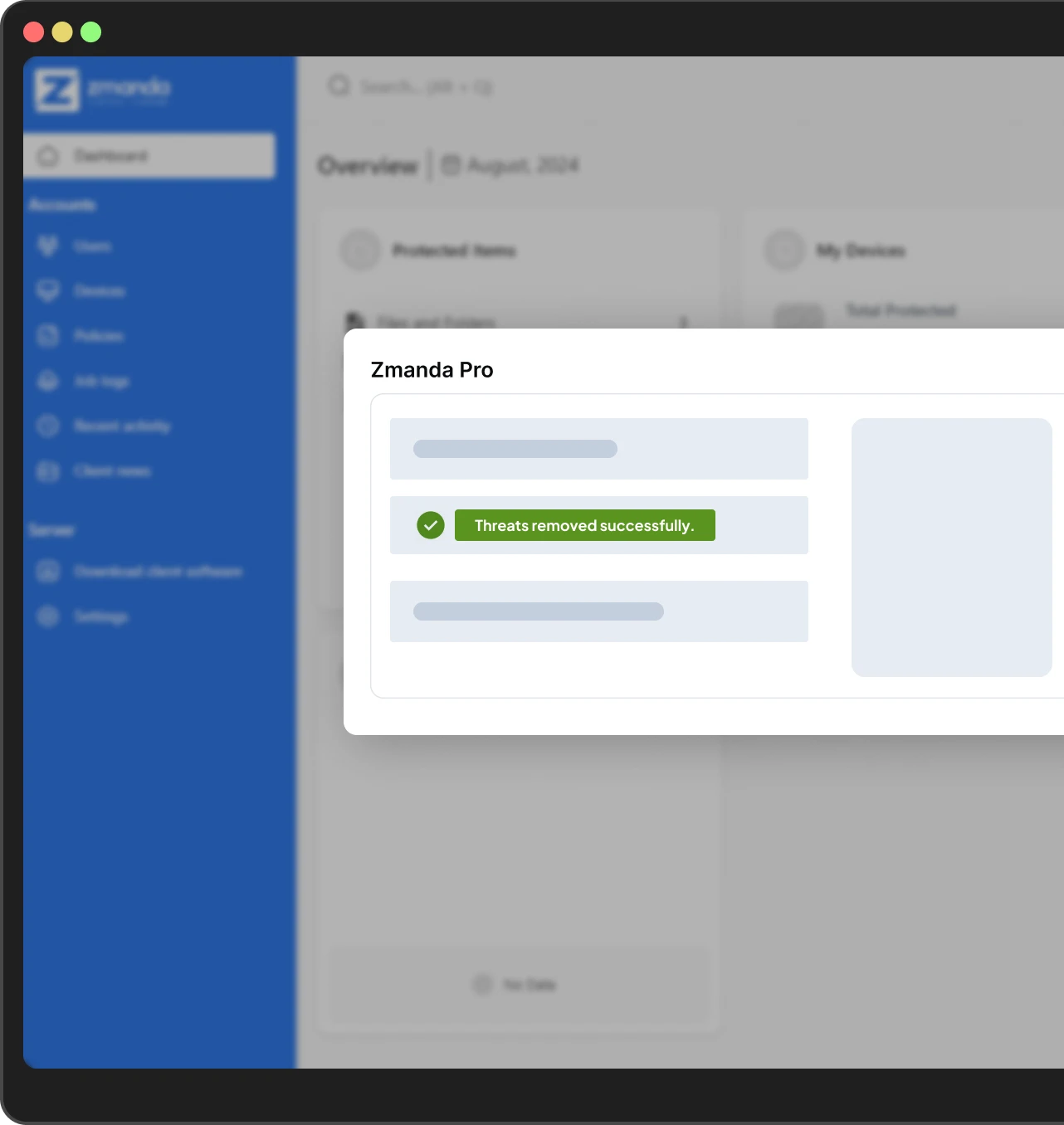
4. Respond to threats quickly
Securely and quickly delegate responsibilities to team members using SSO integration. Automatically execute restores or pause backups if an anomaly is detected using APIs while remotely managing all jobs across geographically dispersed locations from a single pane of glass.
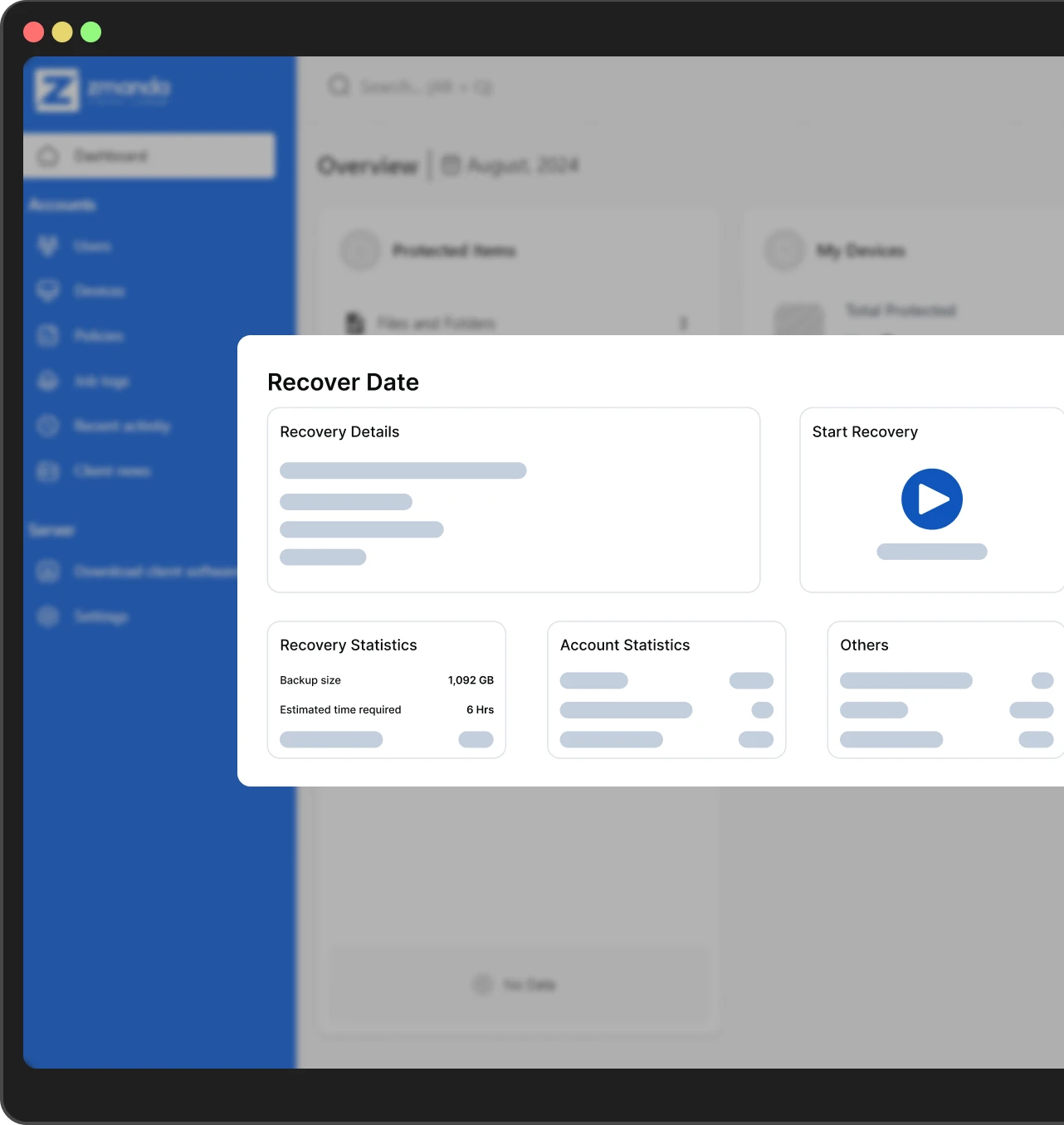
5. Recover to normal operations
Achieve optimized RPO and RTO with flexible scheduling and forever incremental backups. Seamlessly migrate and recover data from clouds (Azure, AWS, GCP, etc.) to on-prem targets, regardless of where the data originated.
Trusted by enterprises worldwide


Zmanda partners with the market leaders

Here’s how Zmanda simplifies data protection


MANAGE LICENSES
Subscription Management
VIRTUALIZATION
VMware to Hyper-V Migration
MANAGE LICENSES
Account Zmanda
Expanded workload support for maximum protection
We provide data protection with support for servers, disk images, databases, virtual machines, applications and
workstations. Adapt to evolving business needs with a scalable solution that grows with your data requirements.
RPO and fast RTO
With flexible scheduling and retention policies and automated bulk recovery, achieve your RPO and RTO requirements
Reduced storage costs
Use deduplication to optimize bandwidth, reduce network load, and increase the efficiency of backups.
Customer satisfaction
From onboarding to technical support, our experts remain available around the clock. 2X higher customer satisfaction than the industry average.
Zmanda grows with your needs
Enterprises
Ideal for complex petabyte-scale enterprises handling large workloads, including databases over 25TB.
Learn moreSMBs
Cost-effective and easy-to-manage backup options, tailored to fit smaller environments without compromising on reliability.
Learn moreHow Zmanda fares against the competition
| Feature | |||
|---|---|---|---|
| TCO savings |
50% lower TCO
|
Higher initial cost,
annual increases |
40% lower TCO
|
| Licensing model |
Simple & predictable
(Per-workload) |
Veeam Universal License
(VUL); Sold in packs of 5 or 10 |
Per-workload or per-GB
monthly subscription |
| Annual cost (100 VMs/workstations) |
$7,188 - $8,388
Predictable, stable pricing |
$14,000 - $21,500
(4-8% increase in 2025) |
$10,000 - $15,000
Variable based on storage |
| Ideal for |
Highly secure offline & hybrid-
cloud environments, air-gap protection |
VMware-centric environments,
complex replication needs |
Minimal IT infrastructure,
saas-heavy environments |