Have you ever considered how much of your organization’s resources are wasted on inefficient data backup and storage? A recent study: IDC StorageSphere Forecast 2023-2028 by International Data Corporation found that the global datasphere is projected to reach 181 zettabytes by 2025, indicating a 64% increase from 2018. With data growing exponentially, the traditional methods of backup are no longer sustainable. So, looking for backup solutions that are built around optimizing backup efficiency and restore processes should be on your radar.
In this article, we’ll explore data-dependent chunking and deduplication—a game-changing technique for optimizing backup efficiency.
But first…
What’s Wrong with Traditional Backup Methods for Optimizing Backup Efficiency?
Traditional backup methods involve taking an initial full backup, followed by a series of incremental or differential backups to capture subsequent changes. While this does provide the ability to restore all the necessary data, it also stores several copies of the unchanged portions of specific files. The inefficiencies multiply when there are several instances of the same file in each filesystem or even a backup set.
Deduplication and Data-Dependent Chunking: Breaking it Down
Data-dependent chunking (DDC) and deduplication take a more intelligent approach. This method involves breaking down data into smaller, variable-sized chunks based on the actual file content. This method ensures that only modified or unique data chunks are processed during backup and restore operations.
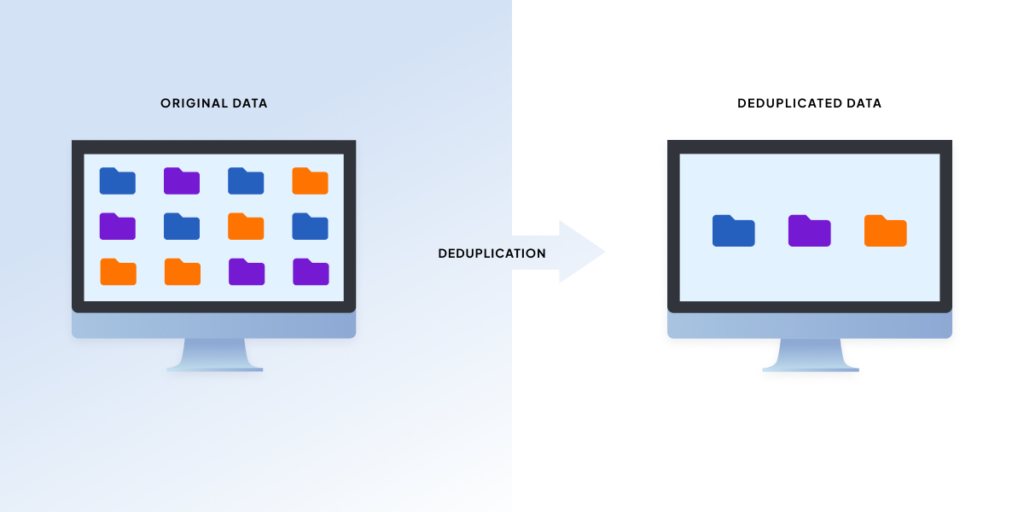
How Deduplication and Data-Dependent Chunking Works – The Backpacking Analogy
Imagine that you’re planning a backpacking trip with your friends. You each lay out all your gear – your tent and poles, hiking sticks, food, water, shoes, etc.
Now, anyone who’s been backpacking knows that weight reduction is essential. So, what do you do when one of your friends shows up with 25 cans of Boston baked beans?
You start deduplicating.
You take out a pencil and paper and begin inventorying. For each new item, you note what it is (e.g., a bean, or a tent pole segment) and its parent item (e.g., a can of beans, or tent pole) before adding it to your backpack. When you encounter an identical item, you simply make a tally next to the original note and set the duplicate aside.
After this process, your inventory might look something like this:
| In your Backpack (Qty 1) | Part of… | # of Duplicates |
| Tent Pole Segment | Tent Pole | 10 |
| Bean | Can of beans | 10,000 |
| Aluminum can for beans | Can of beans | 25 |
| Tent Shell | Tent | 1 |
| Drop of Water | Jug of Water | 1,000,000 |
| Down feather | Sleeping bag | 1,000,000 |
This method significantly reduces the weight you carry – carrying the items, along with the list is much easier to transport and store than all the items and their duplicates. illustrating the essence of deduplication. But how does this relate to data backup?
Translating the Analogy to Data Backup
In the context of data management, the items in your backpack represent unique data chunks, while the duplicates set aside are like redundant data in your storage system. Just as you wouldn’t carry multiple identical cans of beans on a hike, deduplication technology ensures that only one instance of each data piece is stored, no matter how many times it appears across your files.
Data-dependent chunking takes this a step further by analyzing and storing data in variable-sized chunks based on its content, much like deciding whether to pack the whole can of beans or just the amount you need. This approach allows for more efficient storage and faster backup and restore processes, as only the unique or changed chunks are handled during these operations.
3 Different Levels of Deduplication for Optimizing Backup Efficiency
Although, there are 3 different approaches in which deduplication can be achieved—there’s a reason why data-dependent chunking is the most efficient over the others. Let’s jump into each approach, and list out their pros and cons to figure out why data-dependent chunking works best for huge datasets.
- File Level Deduplication– This method operates on a whole-file basis, identifying and storing only one instance of each file, regardless of how many times it appears. Think back to our camping analogy: it’s akin to packing just one can of beans, regardless of how many you might need or have.
Pros:
- Simplicity: It’s straightforward to implement, requiring minimal changes to existing systems.
- Effectiveness for Duplicates: Ideal for environments with many identical files, ensuring a clean, deduplicated storage space.
Cons: - Limited Scope: Struggles with files that have minor differences, leading to inefficiencies in storage for frequently updated files.
- Overlooked Details: Can’t identify duplicate content within a file, potentially leaving redundant data untouched.
- Fixed Block Deduplication– This method deduplicates files based on a fixed block size. This block size can be configurable or hard coded depending on the software and can deduplicate blocks of data within and across files
Pros:
- Granularity: Offers a more detailed approach than file-level deduplication, capable of identifying duplicate blocks within and across files.
- Improved Efficiency: Generally achieves better deduplication ratios by focusing on smaller, fixed-size pieces of data.
Cons: - Rigid Structure: The fixed size of blocks can limit effectiveness, as duplicates that don’t align perfectly with block boundaries may be missed.
- Complexity: Configuring and maintaining the optimal block size requires a delicate balance to maximize efficiency.
- Variable Block or Data-Dependent Deduplication – This is the method that we have been discussing all along. It dynamically adjusts the chunk size based on the data itself, ensuring that each piece of data is stored only once, regardless of its size or location within the file.
Pros:
- Optimal Efficiency: By adjusting chunk sizes to fit the data, it maximizes storage and network efficiency, making it the gold standard for deduplication.
- Resource Optimization: Reduces the need for storage space and bandwidth, optimizing overall system performance.
Con: - Its sophisticated approach requires more advanced setup and management, potentially overcomplicating scenarios where simpler methods might suffice.
So, if you’re handling extensive datasets, the flexibility and efficiency of data-dependent chunking are unparalleled. While file-level and fixed block deduplication have their merits, especially in specific contexts, the adaptive nature of variable block deduplication aligns seamlessly with the complexities and dynamism of large-scale data environments. It’s not just about saving space; it’s about intelligently managing data to support rapid access, recovery, and scalability.
7 Benefits of Data-Dependant Chunking(DDC) and Deduplication for Optimizing Backup Efficiency
While the analogy of not wanting to lug around a 60lb backpack on a hike is relatable, the concept of data-dependent chunking and deduplication brings this idea into the digital space.
Here’s how these techniques transform data backup and storage:
- Efficient storage utilization: DDC and dedupe focus on eliminating redundant data, ensuring that only unique or changed data chunks are stored. This approach significantly reduces storage needs, making the use of storage resources both more economical and efficient.
- Faster data processing: Only one copy of each unique chunk needs to be compressed and encrypted for backups and decrypted and decompressed for restores. This drastically reduces the time and resources required to perform these operations.
- Optimized network performance: During backup and restore operations, only the unique data chunks are transferred between the source and the storage location. This means that for any given operation, only the data that is absent or has changed is moved, enhancing the efficiency of data transmission and significantly reducing network load.
- Enhanced scalability: The reduction in data redundancy not only saves space but also supports greater scalability. Organizations often report seeing data size reductions of up to 30% or more, which translates to being able to store significantly more data in the same amount of storage space.
- Reduced storage costs: It may sound like we’re repeating ourselves, and it’s because we are. But it’s worth saying again that storage is expensive, and reducing the amount of data you need to store can save you thousands or even tens of thousands of dollars each year in storage expenses alone.
- Minimized impact on production systems: Traditional backup processes can sometimes place a heavy load on production systems, leading to performance issues. Data-dependent chunking minimizes this impact by specifically targeting only the essential data chunks. This ensures that backup processes run smoothly without unduly affecting the day-to-day operations of production systems.
- Improved RTO(Recovery Time Objective): Not only does data-dependent chunking expedite the backup and restore processes, but it also enhances data retrieval speeds. When the need arises to access specific data, the selective processing approach allows for quicker retrieval, reducing the overall downtime in critical situations.
Data-dependant Chunking and Deduplication for Optimizing Backup Efficiency with Zmanda
Zmanda has a track record of delivering reliable and efficient backup and recovery for large enterprises. Our latest version – Zmanda Pro is known for its robust and efficient deduplication technology, and fast, air-gapped immutable backups.
Check out our compatibility matrix to understand how well the Zmanda Pro Backup solution can be implemented in your existing environment, or take a 14-day free trial to experience the product firsthand.


