Blog
JUST IN : Latest updates and features

Mastering RTO and RPO Challenges: Expert Solutions
Introduction Ever experienced that heart-stopping moment when your server throws a tantrum and y...
RESOURCE LIBRARY

Navigating Large Data Backup to Public Cloud: Challenges & Best Practices
In the era of big data, storing and managing petabytes of data is the new norm. There is a need to ...

Introducing Zmanda Endpoint Backup 2.7: Refined Continuous Data Protection
Organizations face a number of challenges when it comes to protecting their data, including device ...

Protecting Your Enterprise Data From Ransomware Attacks: 3 Effective Strategies
Ransomware attacks have risen by 13% in the last five years, with an average cost of $1.85 million ...

How to Protect Your Data from Cyber Threats with Zmanda
Data protection has become more critical than ever before. Cyber threats such as data breaches, ran...

Hybrid Cloud Backup and Recovery: Challenges and Opportunities
Data loss is a significant risk for businesses, and it can be costly. The longevity of a business d...

The Benefits of Backup Automation: Saving Time and Resources for Your Enterprise
Enterprises generate vast amounts of data every day, making effective backup solutions essential fo...
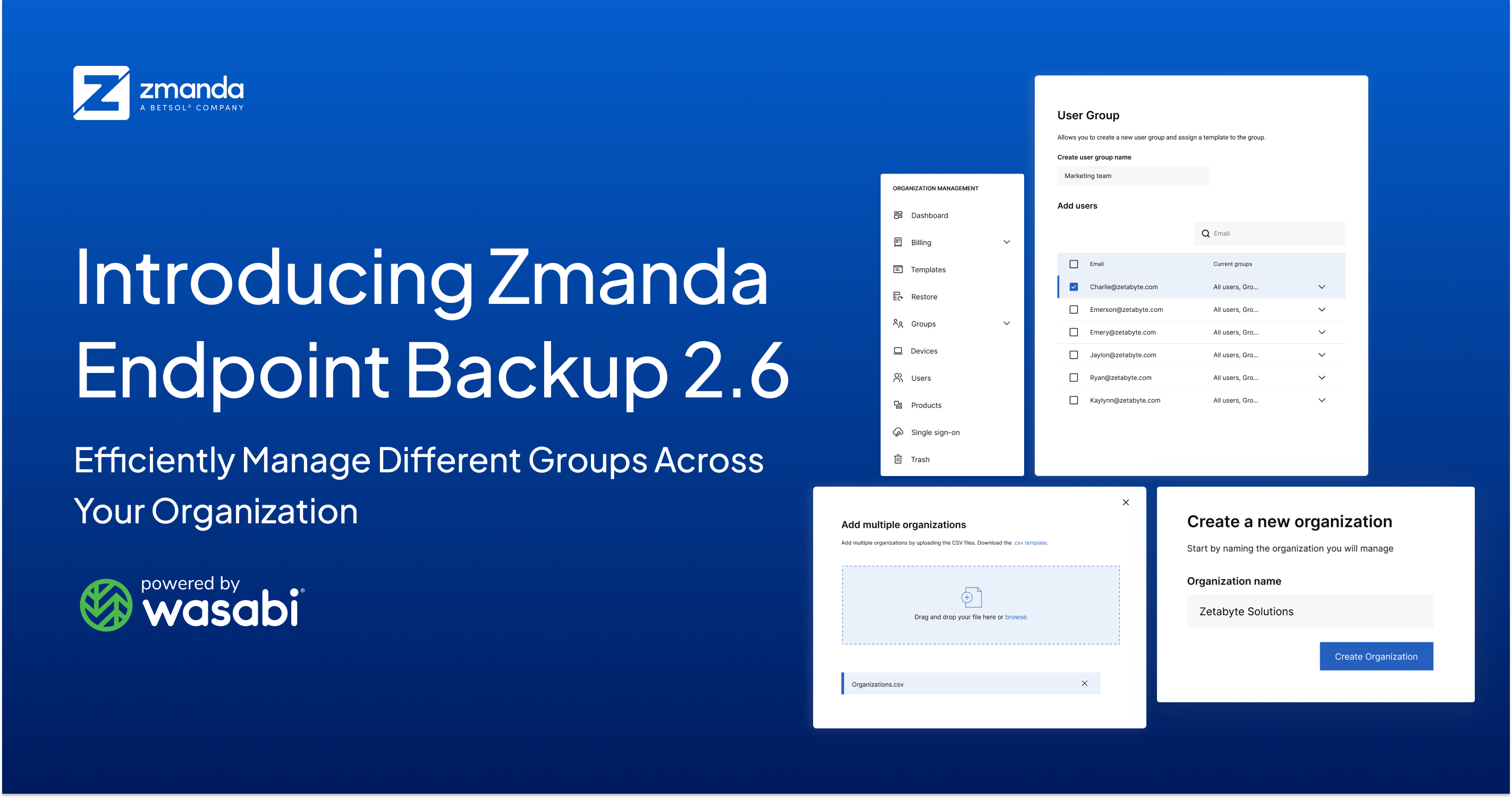
Introducing Zmanda Endpoint Backup 2.6: Efficiently Manage Different Groups Across Your Organization
Zmanda Endpoint Backup 2.6 introduces User Groups functionality and various other customer-requeste...
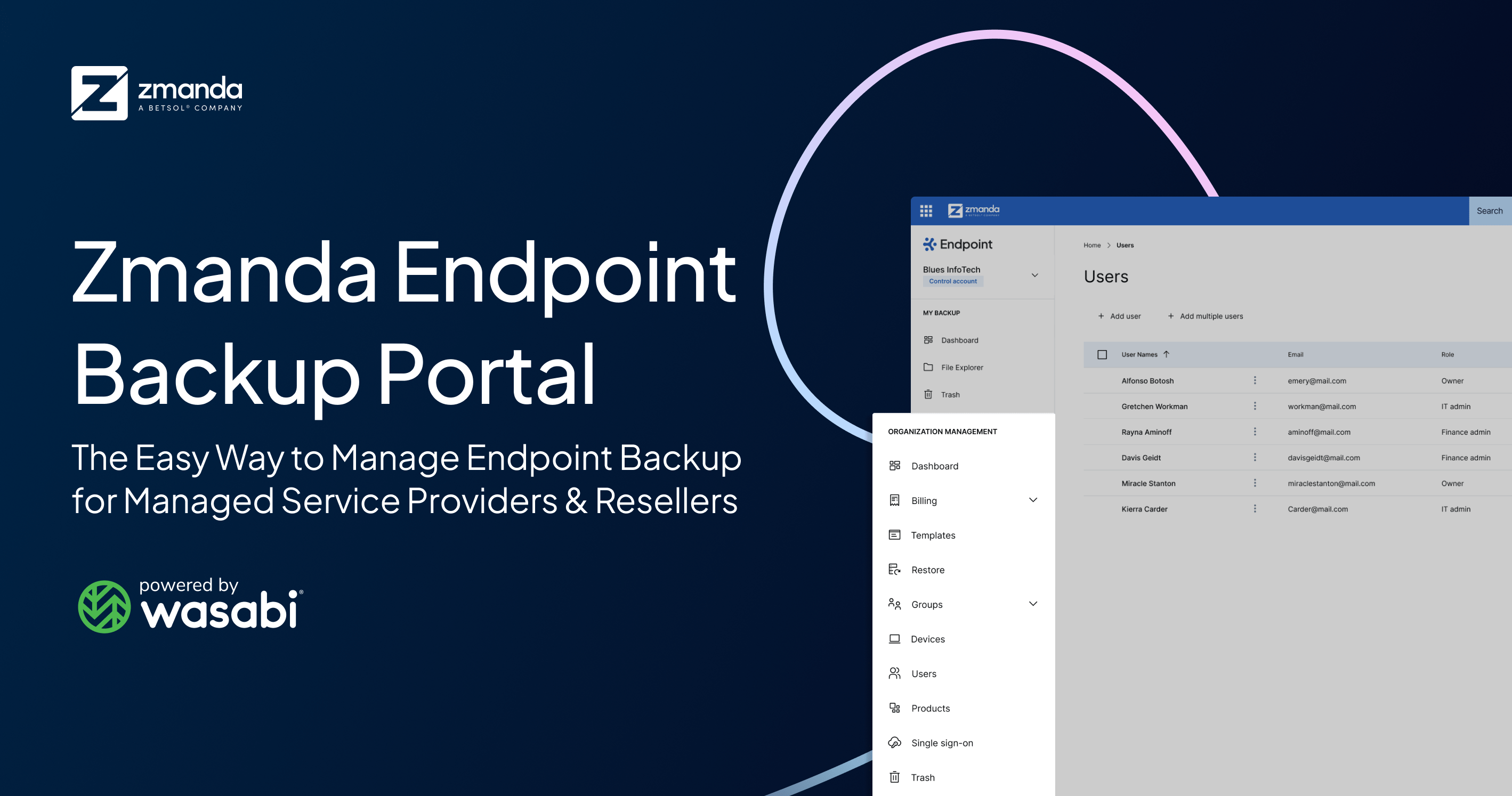
Zmanda Endpoint Backup Portal: The Easy Way to Manage Endpoint Backup for Managed Service Providers & Resellers
Key features of Zmanda Endpoint Backup Portal: Centralized subaccount and organization manageme...

Top 7 Trends in Open-Source Backup Solutions for Cost-Effective Data Protection
For businesses, safeguarding crucial data and ensuring uninterrupted operations rely heavily on bac...