
Heeft u er ooit bij stilgestaan hoeveel van de middelen van uw organisatie worden verspild aan inefficiënte gegevensback-up en -opslag? Een recente studie: IDC StorageSphere-voorspelling 2023-2028 van International Data Corporation ontdekte dat de mondiale datasfeer naar verwachting zal reiken 181 zettabyte tegen 2025, wat wijst op een 64% stijging vanaf 2018. Nu het aantal data exponentieel groeit, zijn de traditionele back-upmethoden niet langer duurzaam. U moet dus op uw radar letten op het zoeken naar back-upoplossingen die zijn gebouwd rond het optimaliseren van de back-upefficiëntie en herstelprocessen.
In dit artikel onderzoeken we gegevensafhankelijke chunking en deduplicatie, een baanbrekende techniek voor het optimaliseren van de back-upefficiëntie.
Maar eerst…
Wat is er mis met traditionele back-upmethoden voor het optimaliseren van de back-upefficiëntie?
Traditionele back-upmethoden omvatten het maken van een eerste volledige back-up, gevolgd door een reeks incrementele of differentiële back-ups om daaropvolgende wijzigingen vast te leggen. Hoewel dit de mogelijkheid biedt om alle benodigde gegevens te herstellen, worden er ook meerdere kopieën van de onveranderd gedeelten van specifieke bestanden. De inefficiënties worden groter als er meerdere exemplaren van hetzelfde bestand in elk bestandssysteem of zelfs in een back-upset voorkomen.
Deduplicatie en data-afhankelijke chunking: het opsplitsen
Data-afhankelijke chunking (DDC) en deduplicatie hebben een intelligentere aanpak. Deze methode omvat het opsplitsen van gegevens in kleinere brokken van variabele grootte op basis van de daadwerkelijke bestandsinhoud. Deze methode zorgt ervoor dat alleen gewijzigde of unieke gegevensfragmenten worden verwerkt tijdens back-up- en herstelbewerkingen.
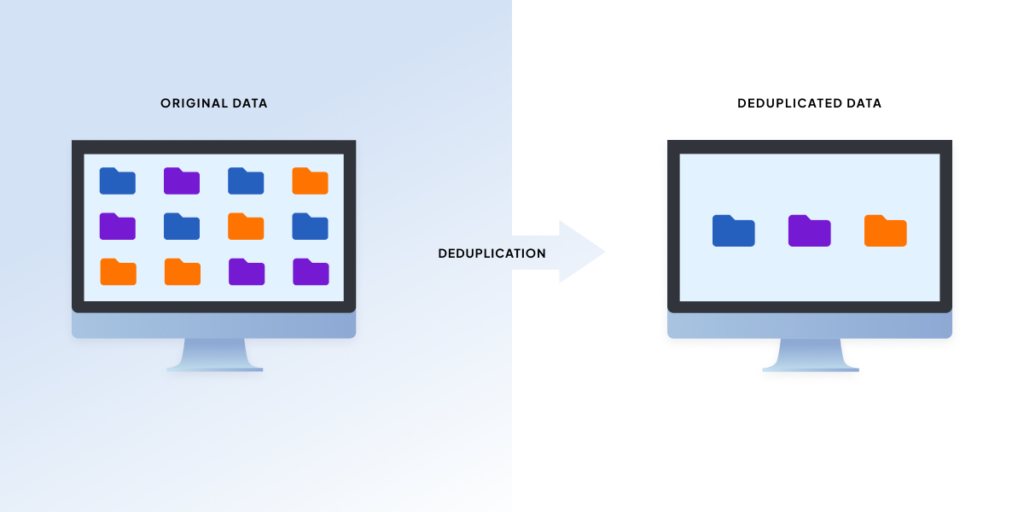
Hoe deduplicatie en data-afhankelijke chunking werken – de backpack-analogie
Stel je voor dat je een backpacktocht plant met je vrienden. Jullie leggen allemaal al je spullen neer: je tent en stokken, wandelstokken, eten, water, schoenen, enz.
Iedereen die aan het backpacken is, weet dat gewichtsvermindering essentieel is. Dus, wat doe je als een van je vrienden opduikt met 25 blikjes Boston-gebakken bonen?
Je begint met ontdubbelen.
Je pakt potlood en papier en begint met inventariseren. Voor elk nieuw item noteer je wat het is (bijvoorbeeld een boon of een segment van een tentstok) en het ouderitem (bijvoorbeeld een blik bonen of een tentstok) voordat je het aan je rugzak toevoegt. Wanneer u een identiek item tegenkomt, maakt u eenvoudigweg een telling naast de originele notitie en legt u het duplicaat opzij.
Na dit proces kan uw inventaris er ongeveer zo uitzien:
| In je rugzak (aantal 1) | Deel van… | Aantal duplicaten |
| Tentstoksegment | Tent paal | 10 |
| Boon | Blik bonen | 10,000 |
| Aluminium blikje voor bonen | Blik bonen | 25 |
| Tent schelp | Tent | 1 |
| Waterdruppel | Kruik water | 1,000,000 |
| Donzen veer | Slaapzak | 1,000,000 |
Deze methode vermindert het gewicht dat u draagt aanzienlijk; het dragen van de items, samen met de lijst, is veel gemakkelijker te vervoeren en op te slaan dan alle items en hun duplicaten. illustreert de essentie van deduplicatie. Maar hoe verhoudt dit zich tot gegevensback-up?
De analogie vertalen naar gegevensback-up
In de context van databeheer vertegenwoordigen de items in uw rugzak unieke gegevensbrokken, terwijl de duplicaten die opzij worden gezet, als redundante gegevens in uw opslagsysteem zijn. Net zoals u tijdens een wandeling niet meerdere identieke blikken bonen meeneemt, zorgt deduplicatietechnologie ervoor dat slechts één exemplaar van elk gegevensstuk wordt opgeslagen, ongeacht hoe vaak dit in uw bestanden voorkomt.
Data-afhankelijke chunking gaat nog een stap verder door data te analyseren en op te slaan in chunks van variabele grootte op basis van de inhoud, net zoals je besluit of je het hele blik bonen moet verpakken of alleen de hoeveelheid die je nodig hebt. Deze aanpak zorgt voor efficiëntere opslag en snellere back-up- en herstelprocessen, omdat tijdens deze bewerkingen alleen de unieke of gewijzigde delen worden verwerkt.
3 verschillende niveaus van ontdubbeling voor het optimaliseren van de back-upefficiëntie
Hoewel er drie verschillende benaderingen zijn waarin deduplicatie kan worden bereikt, is er een reden waarom data-afhankelijke chunking het meest efficiënt is ten opzichte van de andere. Laten we elke aanpak eens bekijken en de voor- en nadelen ervan opsommen om erachter te komen waarom data-afhankelijke chunking het beste werkt voor enorme datasets.
- Ontdubbeling op bestandsniveau– Deze methode werkt op basis van het hele bestand, waarbij slechts één exemplaar van elk bestand wordt geïdentificeerd en opgeslagen, ongeacht hoe vaak het voorkomt. Denk eens terug aan onze kampeeranalogie: het lijkt op het inpakken van slechts één blik bonen, ongeacht hoeveel je er nodig hebt of hebt.
Voors:
- Eenvoud: Het is eenvoudig te implementeren en vereist minimale wijzigingen aan bestaande systemen.
- Effectiviteit voor duplicaten: Ideaal voor omgevingen met veel identieke bestanden, waardoor een schone, gededupliceerde opslagruimte wordt gegarandeerd.
nadelen: - Beperkte reikwijdte: Worstelt met bestanden die kleine verschillen hebben, wat leidt tot inefficiëntie in de opslag van vaak bijgewerkte bestanden.
- Over het hoofd geziene details: Kan geen dubbele inhoud in een bestand identificeren, waardoor overtollige gegevens mogelijk onaangeroerd blijven.
- Vaste blokontdubbeling– Deze methode ontdubbelt bestanden op basis van een vaste blokgrootte. Deze blokgrootte kan afhankelijk van de software configureerbaar of hardgecodeerd zijn en kan gegevensblokken binnen en tussen bestanden ontdubbelen
Voors:
- Granulariteit: Biedt een meer gedetailleerde aanpak dan deduplicatie op bestandsniveau, waarbij dubbele blokken binnen en tussen bestanden kunnen worden geïdentificeerd.
- Verbeterde efficiëntie: bereikt over het algemeen betere deduplicatieratio's door zich te concentreren op kleinere stukjes gegevens met een vaste grootte.
nadelen: - Stijve structuur: De vaste grootte van blokken kan de effectiviteit beperken, omdat duplicaten die niet perfect aansluiten bij de blokgrenzen gemist kunnen worden.
- Complexiteit: Het configureren en onderhouden van de optimale blokgrootte vereist een delicaat evenwicht om de efficiëntie te maximaliseren.
- Variabel blok or Gegevensafhankelijke deduplicatie – Dit is de methode waar we de hele tijd over hebben gesproken. Het past de chunkgrootte dynamisch aan op basis van de gegevens zelf, zodat elk stukje gegevens slechts één keer wordt opgeslagen, ongeacht de grootte of locatie in het bestand.
Voors:
- Optimale efficiëntie: Door de chunkgrootte aan te passen aan de gegevens, wordt de opslag- en netwerkefficiëntie gemaximaliseerd, waardoor dit de gouden standaard voor deduplicatie wordt.
- Optimalisatie van hulpbronnen: Vermindert de behoefte aan opslagruimte en bandbreedte, waardoor de algehele systeemprestaties worden geoptimaliseerd.
Con: - De geavanceerde aanpak vereist een geavanceerdere installatie en beheer, waardoor scenario's waarin eenvoudigere methoden kunnen volstaan mogelijk te ingewikkeld worden.
Dus als u met uitgebreide datasets werkt, zijn de flexibiliteit en efficiëntie van data-afhankelijke chunking ongeëvenaard. Hoewel deduplicatie op bestandsniveau en op vaste blokken hun voordelen hebben, vooral in specifieke contexten, sluit het adaptieve karakter van deduplicatie van variabele blokken naadloos aan bij de complexiteit en dynamiek van grootschalige dataomgevingen. Het gaat niet alleen om het besparen van ruimte; het gaat om het intelligent beheren van gegevens om snelle toegang, herstel en schaalbaarheid te ondersteunen.
7 voordelen van data-afhankelijke chunking (DDC) en deduplicatie voor het optimaliseren van de back-upefficiëntie
Hoewel de analogie van het niet willen sjouwen met een rugzak van 60 pond tijdens een wandeling herkenbaar is, brengt het concept van data-afhankelijke chunking en deduplicatie dit idee naar de digitale ruimte.
Hier ziet u hoe deze technieken de back-up en opslag van gegevens transformeren:
- Efficiënt opslaggebruik: DDC en dedupe richten zich op het elimineren van overtollige gegevens, zodat alleen unieke of gewijzigde gegevensbrokken worden opgeslagen. Deze aanpak vermindert de opslagbehoeften aanzienlijk, waardoor het gebruik van opslagbronnen zowel zuiniger als efficiënter wordt.
- Snellere gegevensverwerking: Er hoeft slechts één kopie van elk uniek deel te worden gecomprimeerd en gecodeerd voor back-ups en gedecodeerd en gedecomprimeerd voor herstel. Dit vermindert drastisch de tijd en middelen die nodig zijn om deze bewerkingen uit te voeren.
- Geoptimaliseerde netwerkprestaties: Tijdens back-up- en herstelbewerkingen worden alleen de unieke gegevensbrokken overgedragen tussen de bron en de opslaglocatie. Dit betekent dat voor een bepaalde bewerking alleen de gegevens worden verplaatst die ontbreken of zijn gewijzigd, waardoor de efficiëntie van de gegevensoverdracht wordt verbeterd en de netwerkbelasting aanzienlijk wordt verminderd.
- Verbeterde schaalbaarheid: De vermindering van de gegevensredundantie bespaart niet alleen ruimte, maar ondersteunt ook een grotere schaalbaarheid. Organisaties melden vaak dat ze een afname van de datagrootte tot 30% of meer zien, wat zich vertaalt in de mogelijkheid om aanzienlijk meer data op te slaan in dezelfde hoeveelheid opslagruimte.
- Lagere opslagkosten: Het klinkt misschien alsof we onszelf herhalen, en dat komt omdat we dat ook doen. Maar het is de moeite waard om nogmaals te zeggen dat opslag duur is, en dat het verminderen van de hoeveelheid gegevens die u moet opslaan u alleen al duizenden of zelfs tienduizenden dollars per jaar aan opslagkosten kan besparen.
- Minimale impact op productiesystemen: Traditionele back-upprocessen kunnen productiesystemen soms zwaar belasten, wat tot prestatieproblemen leidt. Data-afhankelijke chunking minimaliseert deze impact door zich specifiek te richten op de essentiële data chunks. Dit zorgt ervoor dat back-upprocessen soepel verlopen zonder de dagelijkse werking van productiesystemen onnodig te beïnvloeden.
- Verbeterde RTO (hersteltijddoelstelling): Gegevensafhankelijke chunking versnelt niet alleen de back-up- en herstelprocessen, maar verbetert ook de snelheid waarmee gegevens worden opgehaald. Wanneer de behoefte ontstaat om toegang te krijgen tot specifieke gegevens, zorgt de selectieve verwerkingsaanpak ervoor dat deze sneller kunnen worden opgehaald, waardoor de algehele downtime in kritieke situaties wordt verminderd.
Gegevensafhankelijke chunking en deduplicatie voor het optimaliseren van de back-upefficiëntie met Zmanda
Zmanda heeft een trackrecord in het leveren van betrouwbare en efficiënte back-up en herstel voor grote ondernemingen. Onze nieuwste versie – Zmanda Pro staat bekend om zijn robuuste en efficiënte deduplicatietechnologie en snelle, onveranderlijke backups.
Bekijk onze compatibiliteitsmatrix om te begrijpen hoe goed de Zmanda Pro Backup-oplossing kan worden geïmplementeerd in uw bestaande omgeving, of neem een gratis proefperiode van 14 dagen om het product uit de eerste hand te ervaren.


