
Avez-vous déjà réfléchi à la part des ressources de votre organisation qui est gaspillée en raison d'une sauvegarde et d'un stockage de données inefficaces ? Une étude récente: Prévisions IDC StorageSphere 2023-2028 par International Data Corporation a constaté que la sphère mondiale des données devrait atteindre 181 zettaoctets d'ici 2025, ce qui indique un % D'augmentation 64 à partir de 2018. Avec la croissance exponentielle des données, les méthodes traditionnelles de sauvegarde ne sont plus durables. Ainsi, la recherche de solutions de sauvegarde conçues autour de l’optimisation de l’efficacité des sauvegardes et des processus de restauration devrait être sur votre radar.
Dans cet article, nous explorerons le regroupement et la déduplication dépendant des données, une technique révolutionnaire pour optimiser l'efficacité des sauvegardes.
Mais d'abord…
Quel est le problème avec les méthodes de sauvegarde traditionnelles pour optimiser l'efficacité des sauvegardes ?
Les méthodes de sauvegarde traditionnelles impliquent d'effectuer une sauvegarde complète initiale, suivie d'une série de sauvegardes incrémentielles ou différentielles pour capturer les modifications ultérieures. Bien que cela offre la possibilité de restaurer toutes les données nécessaires, il stocke également plusieurs copies du fichier. inchangé des parties de fichiers spécifiques. Les inefficacités se multiplient lorsqu'il existe plusieurs instances du même fichier dans chaque système de fichiers ou même dans un jeu de sauvegarde.
Déduplication et fragmentation dépendante des données : les décomposer
Le regroupement dépendant des données (DDC) et la déduplication adoptent une approche plus intelligente. Cette méthode consiste à décomposer les données en morceaux plus petits et de taille variable en fonction du contenu réel du fichier. Cette méthode garantit que seuls les blocs de données modifiés ou uniques sont traités lors des opérations de sauvegarde et de restauration.
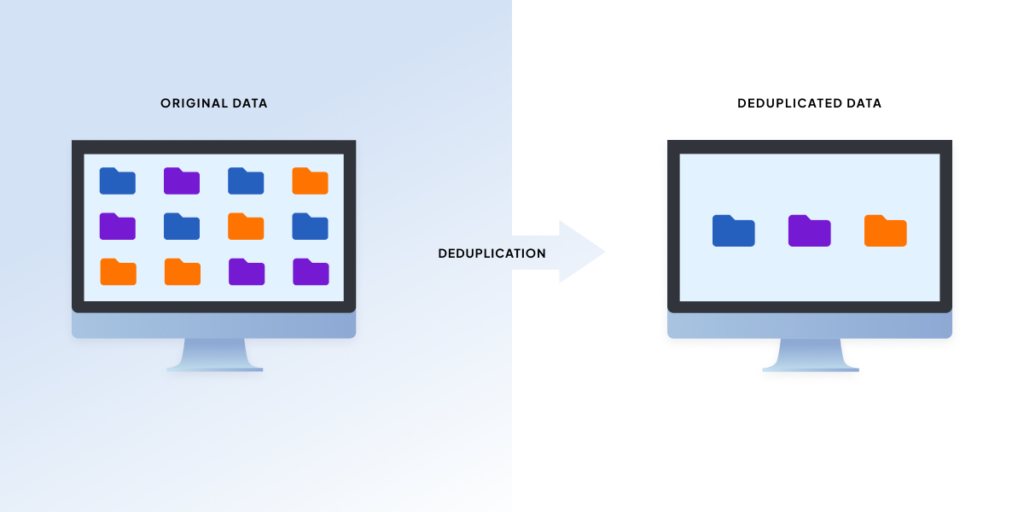
Fonctionnement de la déduplication et du regroupement dépendant des données – L'analogie du sac à dos
Imaginez que vous planifiez un voyage en sac à dos avec vos amis. Vous disposez chacun tout votre équipement : votre tente et vos bâtons, vos bâtons de randonnée, votre nourriture, votre eau, vos chaussures, etc.
Désormais, tous ceux qui ont fait de la randonnée savent que la réduction de poids est essentielle. Alors, que faites-vous lorsqu’un de vos amis se présente avec 25 boîtes de fèves au lard Boston ?
Vous commencez la déduplication.
Vous sortez un crayon et du papier et commencez à inventorier. Pour chaque nouvel élément, vous notez de quoi il s'agit (par exemple, un haricot ou un segment de poteau de tente) et son élément parent (par exemple, une boîte de haricots ou un poteau de tente) avant de l'ajouter à votre sac à dos. Lorsque vous rencontrez un élément identique, il vous suffit de faire un décompte à côté de la note originale et de mettre le double de côté.
Après ce processus, votre inventaire pourrait ressembler à ceci :
| Dans votre sac à dos (Qté 1) | Partie de… | # de doublons |
| Segment de poteau de tente | Mât de tente | 10 |
| Haricot | Boîte de haricots | 10,000 |
| Boîte en aluminium pour haricots | Boîte de haricots | 25 |
| Coquille de tente | Tente | 1 |
| Goutte d'eau | Carafe d'eau | 1,000,000 |
| Duvet | Sac de couchage | 1,000,000 |
Cette méthode réduit considérablement le poids que vous transportez – transporter les éléments ainsi que la liste est beaucoup plus facile à transporter et à stocker que tous les éléments et leurs doublons. illustrant l'essence de la déduplication. Mais quel est le rapport avec la sauvegarde des données ?
Traduire l'analogie avec la sauvegarde des données
Dans le contexte de la gestion des données, les éléments de votre sac à dos représentent des blocs de données uniques, tandis que les doublons mis de côté sont comme des données redondantes dans votre système de stockage. Tout comme vous ne transporteriez pas plusieurs boîtes de haricots identiques lors d'une randonnée, la technologie de déduplication garantit qu'une seule instance de chaque élément de données est stockée, quel que soit le nombre de fois où elle apparaît dans vos fichiers.
Le regroupement dépendant des données va encore plus loin en analysant et en stockant les données dans des morceaux de taille variable en fonction de leur contenu, un peu comme décider s'il faut emballer la boîte de haricots entière ou juste la quantité dont vous avez besoin. Cette approche permet un stockage plus efficace et des processus de sauvegarde et de restauration plus rapides, car seuls les fragments uniques ou modifiés sont traités lors de ces opérations.
3 niveaux différents de déduplication pour optimiser l'efficacité des sauvegardes
Bien qu'il existe trois approches différentes pour réaliser la déduplication, il y a une raison pour laquelle le regroupement dépendant des données est le plus efficace par rapport aux autres. Passons à chaque approche et énumérons leurs avantages et leurs inconvénients pour comprendre pourquoi le découpage dépendant des données fonctionne mieux pour d'énormes ensembles de données.
- Déduplication au niveau des fichiers– Cette méthode fonctionne sur la base d'un fichier entier, identifiant et stockant une seule instance de chaque fichier, quel que soit le nombre d'apparitions. Repensez à notre analogie avec le camping : cela revient à emballer une seule boîte de haricots, peu importe la quantité dont vous pourriez avoir besoin ou dont vous pourriez avoir.
Avantages:
- Simplicité : sa mise en œuvre est simple et nécessite des modifications minimes des systèmes existants.
- Efficacité pour les doublons : Idéal pour les environnements contenant de nombreux fichiers identiques, garantissant un espace de stockage propre et dédupliqué.
Inconvénients: - Portée limitée : difficultés avec les fichiers présentant des différences mineures, entraînant des inefficacités de stockage pour les fichiers fréquemment mis à jour.
- Détails négligés : impossible d'identifier le contenu en double dans un fichier, laissant potentiellement les données redondantes intactes.
- Déduplication de bloc fixe– Cette méthode déduplique les fichiers en fonction d'une taille de bloc fixe. Cette taille de bloc peut être configurable ou codée en dur selon le logiciel et peut dédupliquer des blocs de données dans et entre les fichiers.
Avantages:
- Granularité : offre une approche plus détaillée que la déduplication au niveau des fichiers, capable d'identifier les blocs en double dans et entre les fichiers.
- Efficacité améliorée : permet d'obtenir généralement de meilleurs taux de déduplication en se concentrant sur des éléments de données plus petits et de taille fixe.
Inconvénients: - Structure rigide : la taille fixe des blocs peut limiter l'efficacité, car les doublons qui ne s'alignent pas parfaitement avec les limites des blocs peuvent être manqués.
- Complexité : La configuration et le maintien de la taille de bloc optimale nécessitent un équilibre délicat pour maximiser l'efficacité.
- Bloc variable or Déduplication dépendante des données – C’est la méthode dont nous discutons depuis le début. Il ajuste dynamiquement la taille des fragments en fonction des données elles-mêmes, garantissant que chaque élément de données n'est stocké qu'une seule fois, quel que soit sa taille ou son emplacement dans le fichier.
Avantages:
- Efficacité optimale : en ajustant la taille des blocs pour s'adapter aux données, il maximise l'efficacité du stockage et du réseau, ce qui en fait la référence en matière de déduplication.
- Optimisation des ressources : réduit le besoin d'espace de stockage et de bande passante, optimisant ainsi les performances globales du système.
Avec: - Son approche sophistiquée nécessite une configuration et une gestion plus avancées, ce qui risque de compliquer excessivement les scénarios où des méthodes plus simples pourraient suffire.
Ainsi, si vous gérez de vastes ensembles de données, la flexibilité et l’efficacité du regroupement dépendant des données sont sans précédent. Bien que la déduplication au niveau fichier et par blocs fixes ait ses mérites, en particulier dans des contextes spécifiques, la nature adaptative de la déduplication par blocs variables s'aligne parfaitement avec la complexité et le dynamisme des environnements de données à grande échelle. Il ne s'agit pas seulement d'économiser de l'espace ; il s'agit de gérer intelligemment les données pour prendre en charge un accès, une récupération et une évolutivité rapides.
7 avantages du Data-Dependant Chunking (DDC) et de la déduplication pour optimiser l'efficacité des sauvegardes
Même si l’analogie selon laquelle on ne veut pas trimballer un sac à dos de 60 livres lors d’une randonnée est pertinente, le concept de segmentation et de déduplication dépendant des données amène cette idée dans l’espace numérique.
Voici comment ces techniques transforment la sauvegarde et le stockage des données :
- Utilisation efficace du stockage : DDC et déduplication se concentrent sur l’élimination des données redondantes, garantissant que seuls les morceaux de données uniques ou modifiés sont stockés. Cette approche réduit considérablement les besoins de stockage, rendant l'utilisation des ressources de stockage à la fois plus économique et plus efficace.
- Traitement plus rapide des données : Une seule copie de chaque morceau unique doit être compressée et chiffrée pour les sauvegardes et déchiffrée et décompressée pour les restaurations. Cela réduit considérablement le temps et les ressources nécessaires pour effectuer ces opérations.
- Performances réseau optimisées : Lors des opérations de sauvegarde et de restauration, seuls les blocs de données uniques sont transférés entre la source et l'emplacement de stockage. Cela signifie que pour une opération donnée, seules les données absentes ou modifiées sont déplacées, ce qui améliore l'efficacité de la transmission des données et réduit considérablement la charge du réseau.
- Évolutivité améliorée : La réduction de la redondance des données permet non seulement d'économiser de l'espace, mais permet également une plus grande évolutivité. Les organisations déclarent souvent avoir constaté des réductions de la taille des données allant jusqu'à 30 % ou plus, ce qui se traduit par la possibilité de stocker beaucoup plus de données dans la même quantité d'espace de stockage.
- Coûts de stockage réduits : Cela peut donner l’impression que nous nous répétons, et c’est parce que c’est le cas. Mais il convient de répéter que le stockage coûte cher, et réduire la quantité de données que vous devez stocker peut vous faire économiser des milliers, voire des dizaines de milliers de dollars chaque année rien qu'en dépenses de stockage.
- Impact minimisé sur les systèmes de production : Les processus de sauvegarde traditionnels peuvent parfois imposer une lourde charge aux systèmes de production, entraînant des problèmes de performances. Le regroupement dépendant des données minimise cet impact en ciblant spécifiquement uniquement les blocs de données essentiels. Cela garantit que les processus de sauvegarde se déroulent sans problème sans affecter indûment les opérations quotidiennes des systèmes de production.
- RTO amélioré (objectif de temps de récupération) : Non seulement le regroupement dépendant des données accélère les processus de sauvegarde et de restauration, mais il améliore également les vitesses de récupération des données. Lorsqu'il est nécessaire d'accéder à des données spécifiques, l'approche de traitement sélectif permet une récupération plus rapide, réduisant ainsi le temps d'arrêt global dans les situations critiques.
Regroupement et déduplication dépendant des données pour optimiser l'efficacité des sauvegardes avec Zmanda
Zmanda a fait ses preuves en matière de fourniture de sauvegardes et de restaurations fiables et efficaces pour les grandes entreprises. Notre dernière version – Zmanda Pro est connu pour sa technologie de déduplication robuste et efficace et pour ses sauvegardes immuables rapides et isolées.
Consultez les matrice de compatibilité pour comprendre dans quelle mesure la solution Zmanda Pro Backup peut être implémentée dans votre environnement existant, ou faites un essai gratuit de 14 jours pour expérimenter le produit de première main.


