
Powering Enterprise Data Protection World-Wide
1 million+
Servers protected through Zmanda
45+
Serving customers in 45+ nations
1991
Protecting enterprise
data since 1991.
Rung 2
Certified
Qualified Department of Homeland Security Certification for Government use.
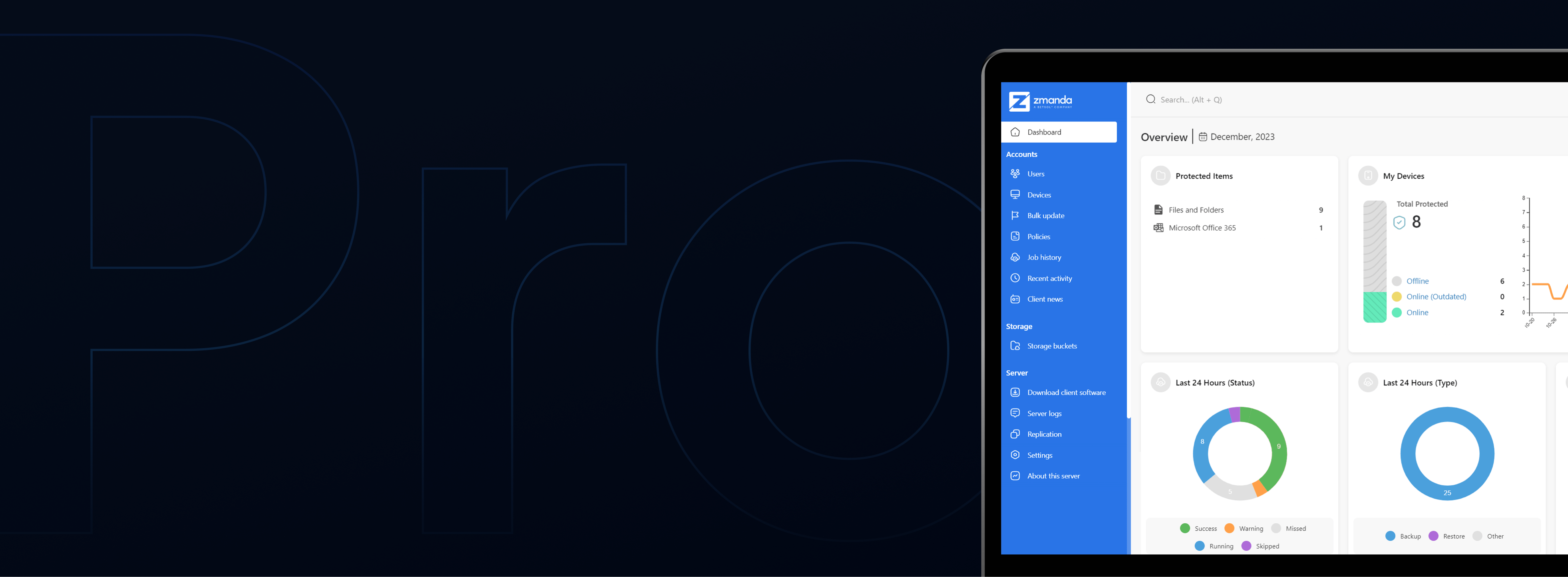
Zmanda Does Everything Like It’s Nothing
All Your Workloads.
One Seamless Experience.

Hear All About the Zmanda Experience
Take a Look at What’s New,
Right Now
The latest insights from our community and experts
Featured Awards &
Industry Recognition

US Homeland
Security Certified
Awarded 'Favorite Backup
Solution' by Linux Journal
Awarded ‘MySQL Partner
of the Year’